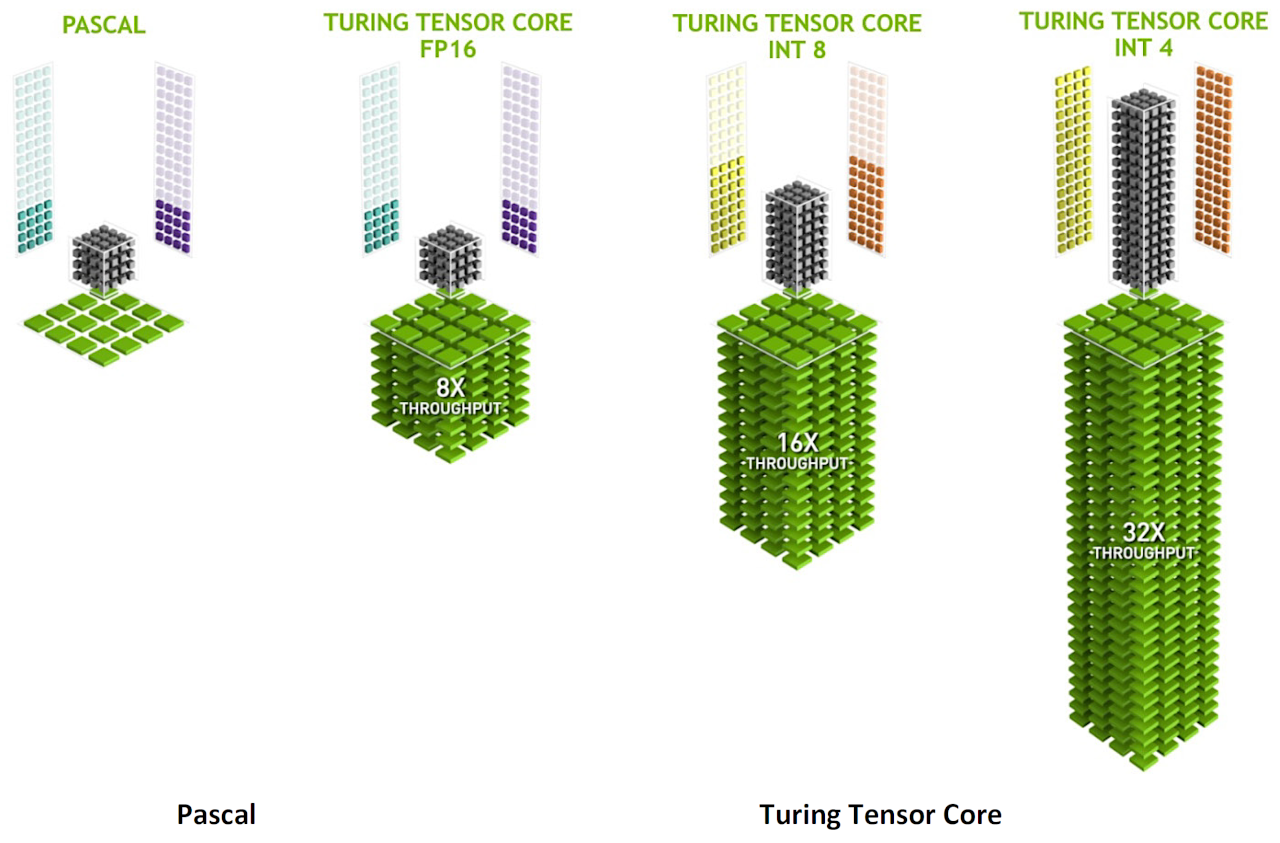
Turing™ GPU には、Volta GV100 GPU で最初に導入された Tensor Cores の拡張バージョンが搭載されています。
Turing™ Tensor Core は、量子化 を許容することができる Workload の推論のために、INT8 と INT4 という低い精度の仕様が追加されています。
より高い精度を必要とする Workload に対応するため、FP16 も完全にサポートされています。
Turing™ ベース の GeForceゲーミングGPU に Tensor Cores を導入することで、リアルタイム の ディープラーニング を ゲームアプリケーション に初めてもたらすことが可能になります。
Turing™ Tensor Cores は、グラフィック、レンダリング、およびその他の種類の クライアントサイドアプリケーション を強化する、NVIDIA
® NGX Neural Services の AIベース の機能を加速します。
NGX AI機能 の例としては、 ディープラーニングスーパーサンプリング(DLSS)、AI InPainting、AI Super Rez、および AI Slow-Mo があります。
Tensor Cores を使用すると、ニューラルネットワーク のトレーニングと推論機能の中核となる、行列間の乗算(matrix-matrix multiplication) が加速されます。
Turing™ Tensor Cores は、推論計算に特に優れています。
推論計算では、与えられた入力に基づいて、訓練された ディープニューラルネットワーク(DNN) によって有用で関連性のある情報を推論して配信できます。
推論の例としては、Facebook の写真で友達の画像を識別、自動運転車の中でさまざまな種類の自動車、歩行者、および道路の危険を識別して分類、人のスピーチをリアルタイムで翻訳、オンライン小売 および ソーシャルメディアシステムでパーソナライズされたユーザー推奨を作成するシステム等があります。
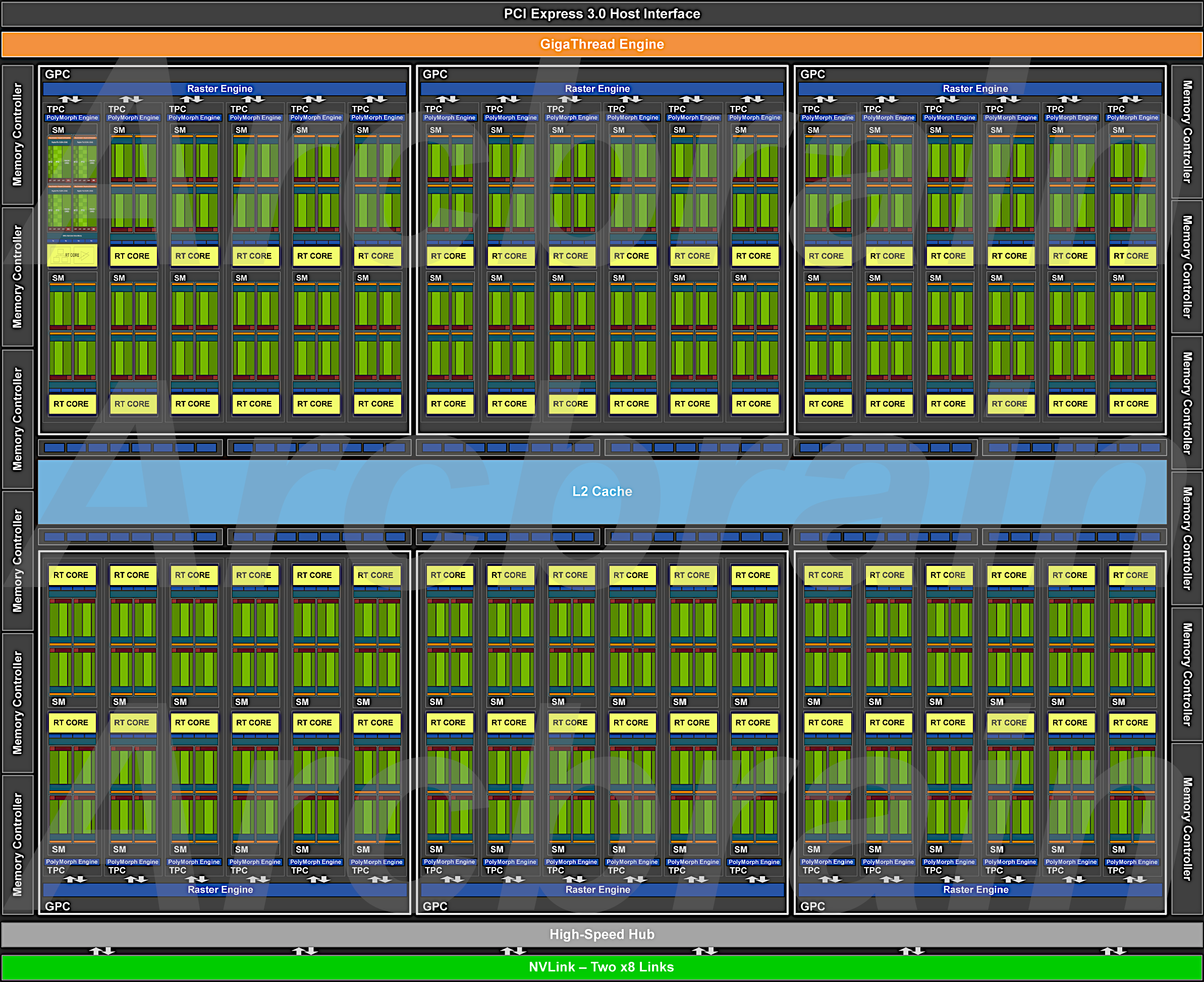
TU102 GPU には 576基( (2[SM] * 4[Processing Block]) * 12 * 6[GPCs]) の Tensor Core が搭載されています。
SM ごとに 8基、SM 内の 4基ある 【Processing Block】 ごとに 各々 2基 搭載されています。
各々の Tensor Core は、FP16入力 を使用して、1クロック あたり 最大 64命令 の 浮動小数点融合積和(FMA:Fused Multiply-Add)演算 を実行できます。
SM 内の 8基 の Tensor Cores は、1クロック あたり 合計512命令 の FP16乗算 および 積和演算(Accumulate Operations)、または 1クロック あたり 1024命令 の FP(浮動小数点)演算 を実行します。
新しい INT8精度モード は、この2倍、つまり クロックあたり 2048命令 の整数演算を実行します。
Turing™ Tensor Cores は行列演算を大幅にスピードアップし、新しい ニューラルグラフィックス機能 に加えて、ディープラーニングトレーニング と 推論演算 の両方に使用されます。
Tensor Core の基本的な運用上の詳細については、
NVIDIA Tesla V100 GPU Architecture Whitepaper
を参照してください。
図4 は、AI推論に多精度を提供する新しい Turing™ Tensor Cores を示しています。








_Checker_1193x2027.png)